
在我的職業生涯中,我有幸參與並見證了多個團隊架構的發展與演變,從最初的小型單一叢集到規模龐大的分散式系統,再到最終達成高度統一的集中化平台。這些寶貴的經歷讓我深刻理解了可觀測性基礎設施在不同階段的需求與挑戰。今天,我將與大家分享我在這個過程中所累積的經驗與洞見,帶領大家了解從最簡單的起步,到面對多集群環境下的複雜問題,如何一步步演進,最終建立起一個能夠支撐龐大業務需求的穩健架構。這是一段從探索到實現的旅程,希望能為你們的架構設計提供一些啟發和方向。
Grafana Lab 曾經在一場對外的演說中表示:「可觀測性基礎設施應該像水和電一樣,自然而然地從牆壁裡出現。如果有一天它們消失了,只需打個電話,它們就能完好如初地恢復運作。」這強調了 Grafana Cloud 將自身定位為專注於提供穩定可觀測性基礎架構的角色,使得使用者能夠在這樣完善的基礎上,建立屬於自己的可觀測性應用服務,最終從這些具有業務邏輯的應用中萃取出最寶貴的見解。
對於我們這些負責團隊中可觀測性基礎設施搭建的人來說,Grafana Cloud 的建構理念和哲學不僅值得細細品味,更能啟發我們對於基礎設施設計的深層思考。從中,我們能夠深刻體會到一個成熟且穩健的基礎設施在長期運營中的重要性。接下來,讓我們一起探索並理解一個優秀的基礎設施如何在需求不斷變化的環境中演變與成長。
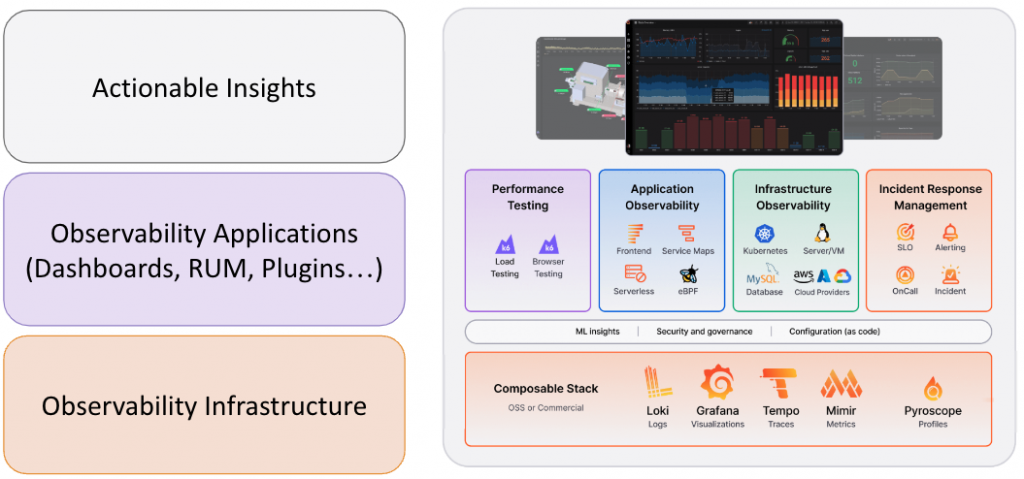
接下來,我們將深入探討一個成熟的中心化架構的演變過程。此過程將以 Grafana 生態系統為主軸,介紹一套具有高度通用性的架構演變方式。在此過程中,所有步驟都可根據實際情況進行最佳化調整,我們所使用的元件和工具也可以根據需求選擇其他同類服務來替代,並不局限於特定的技術或平台。
以下是範例中使用到的主要服務元件的簡單介紹:
在我們的範例中,這些熟悉的 Grafana 生態系相關服務構成了一個完整的可觀測性解決方案,能有效管理和監控複雜的分佈式系統。
在我們最初建立監控或可觀測性架構時,通常會選擇 Prometheus 作為 APM 系統的核心。此時,我們只需要單一叢集和少量節點,就能搭建起一個小規模的監控環境,並逐步實現基礎的監控和告警功能。這是個良好的開端,雖然初期對於故障回應的速度要求不高,但這樣的架構為後續業務的擴展打下了穩固的基礎。隨著業務的增長,我們可以在此基礎上逐步優化,擴展監控範圍,並提升告警和故障處理的效率。
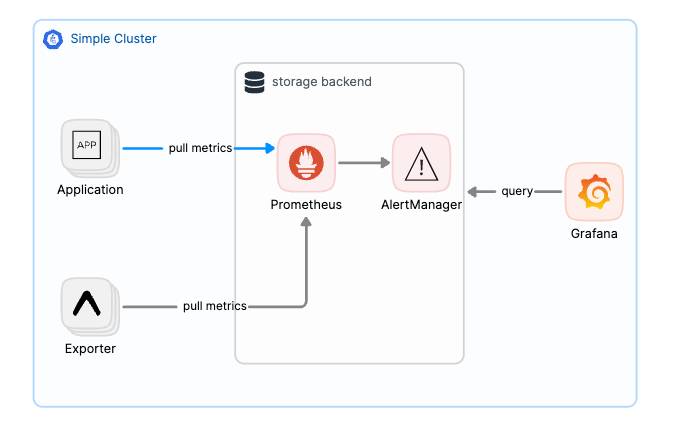
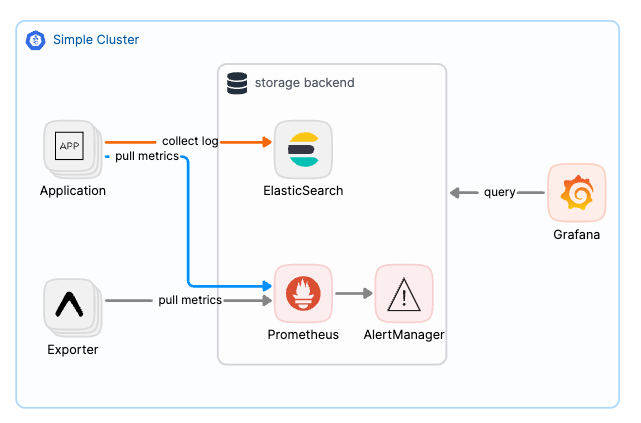
隨著業務增加我們的叢集規模也逐漸擴大,開始出現叢集管理員與開發者角色分工的模式。而登入主機查看基本日誌以逐漸不能滿足開發者對於排查效率及快速回逤並且定位問題源頭的需求了,並且開發者大部分不具備叢集管理員任意登入主機查看日誌的權限。這時,更好的日誌管理解決方案需求出現了,在我個人經驗中,通常第一個被導入的將會是已經成熟並廣為熟之的 ElasticSearch 用來當作日誌管理分析系統。
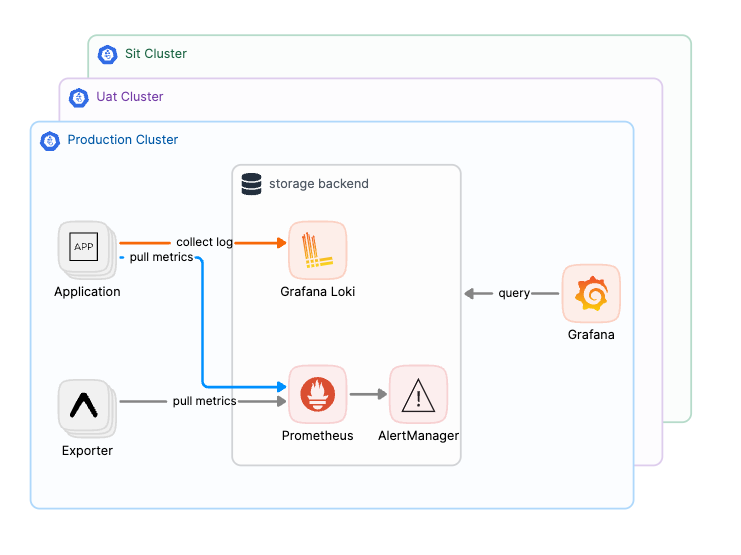
隨著業務的持續增長,我們逐漸發現,單一叢集在管理所有環境和服務時變得日益混亂且難以維護。為了避免「吵雜鄰居效應」帶來的資源競爭問題,我們決定採用多叢集策略,將不同的環境分開管理,並為每個環境部署獨立的監控和日誌系統。
在這個過程中,我們首次意識到,儘管監控和日誌系統(如 ElasticSearch)並不直接參與業務營收,但它們的資源消耗和硬碟成本隨著業務擴張而顯著增加,甚至成為一筆不容忽視的開銷。因此,我們開始尋找更具成本效益的日誌解決方案,最終選擇了雲端物件儲存與高可擴展性的 Grafana Loki,來替代傳統的 ElasticSearch 系統。
總結來說,因為系統業務規模持續的成長,使我們選擇切分了環境,並且為每個環境部署獨立的監控和日誌系統。這一策略不僅降低了成本,還提高了系統的靈活性和可擴展性。
在經歷現實世界中大流量的挑戰後,我們的架構從最初的單體式服務逐步演變為靈活且可擴展的微服務架構。隨著團隊在實際操作中深入體會到「優質服務」的重要性,我們發現,儘管已經擁有完善的監控、告警機制和日誌排查功能,依然難以快速有效地解決複雜的請求鏈路問題。這促使我們開始重視可觀測性訊號的概念,並逐漸認識到分佈式追蹤的需求愈發迫切。為了應對這一挑戰,我們引入了 Grafana Tempo 作為追蹤解決方案,至此,我們完成了可觀測性三大支柱(Metrics、Logs、Traces)的全面收集,進一步提升了我們對系統運行狀態的洞察能力。
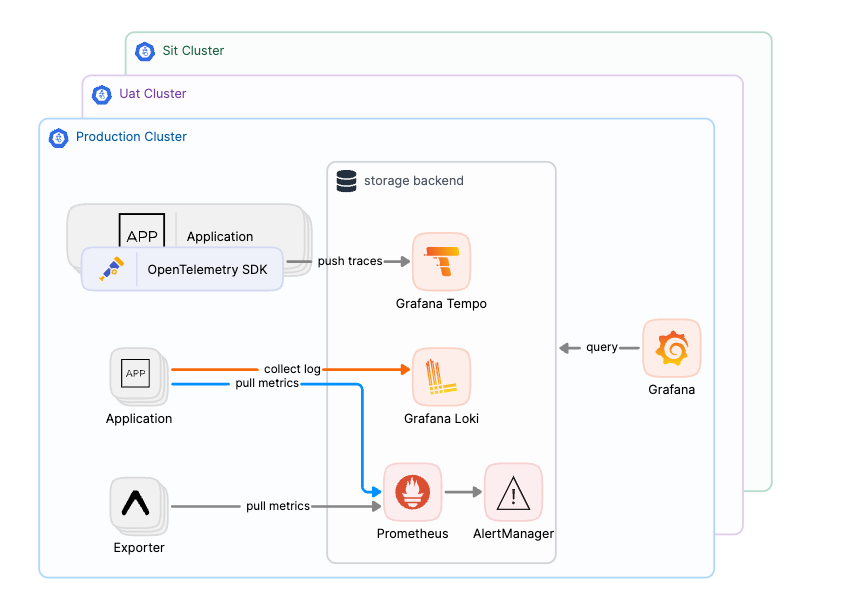
隨著業務的持續增長,公司組織架構變得越來越複雜,角色日益增多。工程部門不再是單一的團隊,而是分化為多個方向和功能各異的團隊。這些團隊對各自使用的環境和服務都有一定的隔離需求。同時,專職的 DevOps/SRE 團隊逐漸成熟,公司也正朝著多部門協作的大型架構邁進。
在這個過程中,叢集的數量從最初的 N 個環境指數性地增長至 X 個部門乘以 N 個環境,這樣的增長顯著提升了管理的複雜度,使得基礎設施的搭建和維護更加具有挑戰性。為了應對這些挑戰,我們開始考慮向中心化架構過渡,首要的步驟是以最小的改動將 Grafana 中心化,並使用 Data Source 來實現各叢集的可視化切換。這種做法不僅有效簡化了管理,還為未來的進一步中心化打下了堅實的基礎。
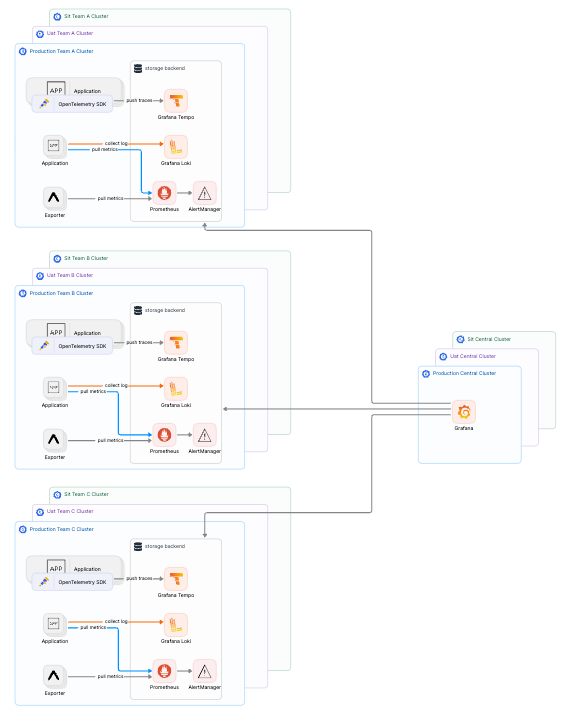
在一個以可觀測性基礎設施中心化為主軸的 DevOps/SRE 團隊中,當我們將告警分散到各個團隊自主管理時,往往會對我們實現統一告警和統一監控的目標產生反效果。各個團隊可能會因為不同的需求和標準,導致告警的誤報、不當使用以及監控的碎片化,這些問題都會削弱我們整體的可觀測性策略。
為了應對這些挑戰,我們決定收斂告警的路由規則,將告警管理統一中心化。通過制定統一的標準,並將這些標準應用於各個部門,我們能夠抽象出關鍵的維度,從而有效地對各團隊進行一致性管理。這不僅提升了告警的準確性和有效性,也確保了我們的可觀測性系統能夠為整個組織提供穩定而可靠的支持。
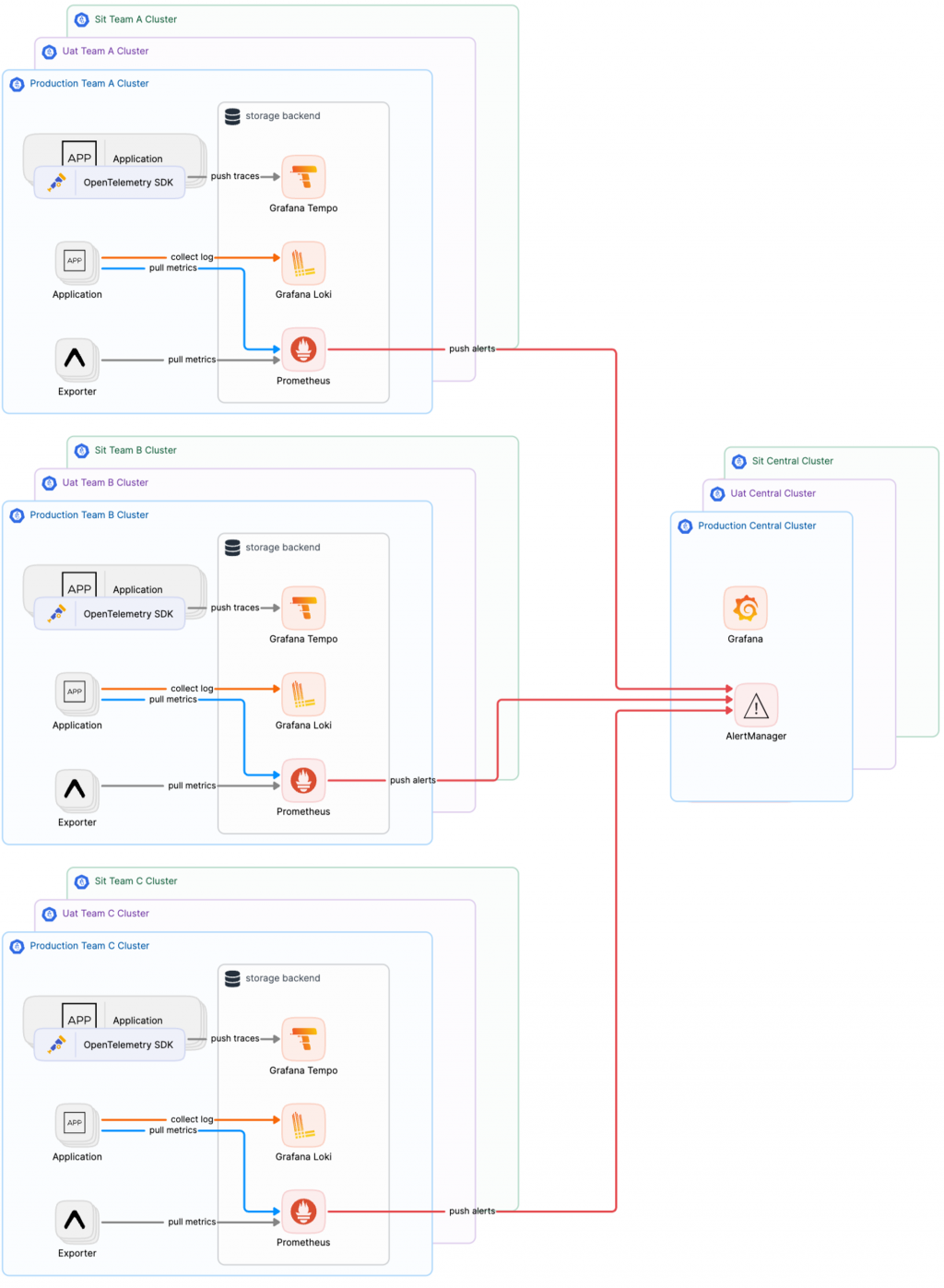
目前,我們的組織已經擁有 X 個團隊和 N 個環境的龐大規模,每個環境都需要一套完整的可觀測性基礎設施。隨著團隊和環境的持續擴大,我們發現自己不得不反覆搭建和維護這些基礎設施,並且成本也隨之上升。當繁重的維護工作逐漸佔據了大量時間時,我們意識到,隨著叢集數量的增加,維護負擔將持續增長。如果不採取有效措施,最終我們將無法應對如此龐大的維護需求。因此,我們決定(或說是不得不)將可觀測性基礎設施轉向中心化架構。如此一來,無論擁有多少個叢集,我們只需維護一套集中管理的可觀測性系統,而不必為每個環境單獨配置和維護多套系統。
在這個轉變過程中,Grafana Alloy 作為叢集級別的可觀測性信號收集者,負責統一處理和整合各種數據格式,並將這些數據輸送至中心化的架構,成為實現中心化的關鍵角色。
當然,要達成這一目標,我們必須確保這些集中化服務能夠保持高度穩定,以支持不斷增長的環境需求。通過這種中心化策略,我們大幅減少了維護的複雜性和工作量,使我們能夠專注於更具價值的任務。
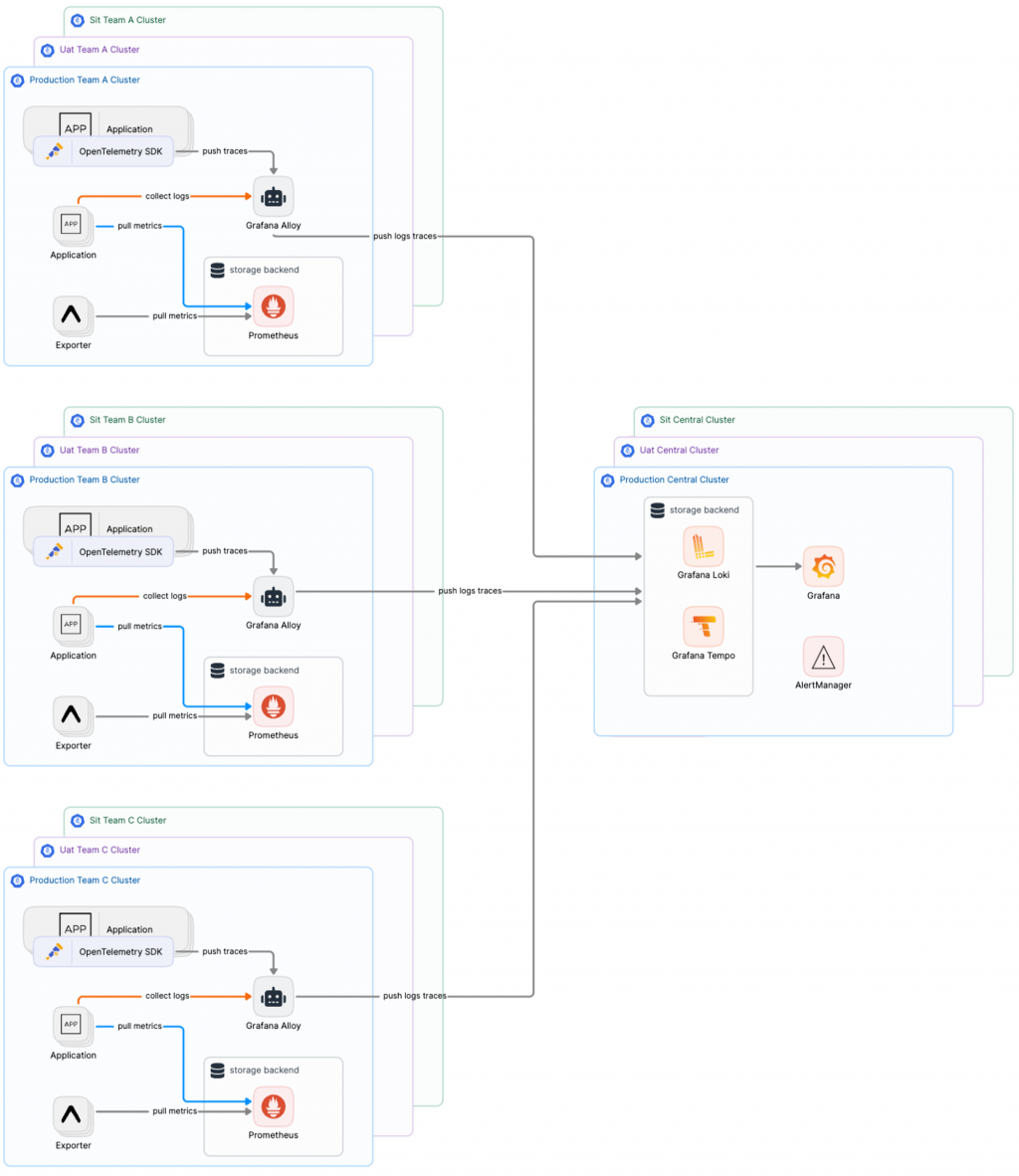
當我們擁有一個穩定的中心化日誌和追蹤解決方案後,我們逐漸發現,單體式 Prometheus 的本地指標儲存能力不足以滿足長期監控需求。對於大型企業而言,監控指標通常需要保存數年,而這正是 Prometheus 的限制。因此,我們決定引入 Mimir 作為長期指標存儲的解決方案,並透過 Prometheus 的 remote write 功能將數據持續寫入這個後端系統。至此,我們的 Grafana LGTM 架構終於初步成形。
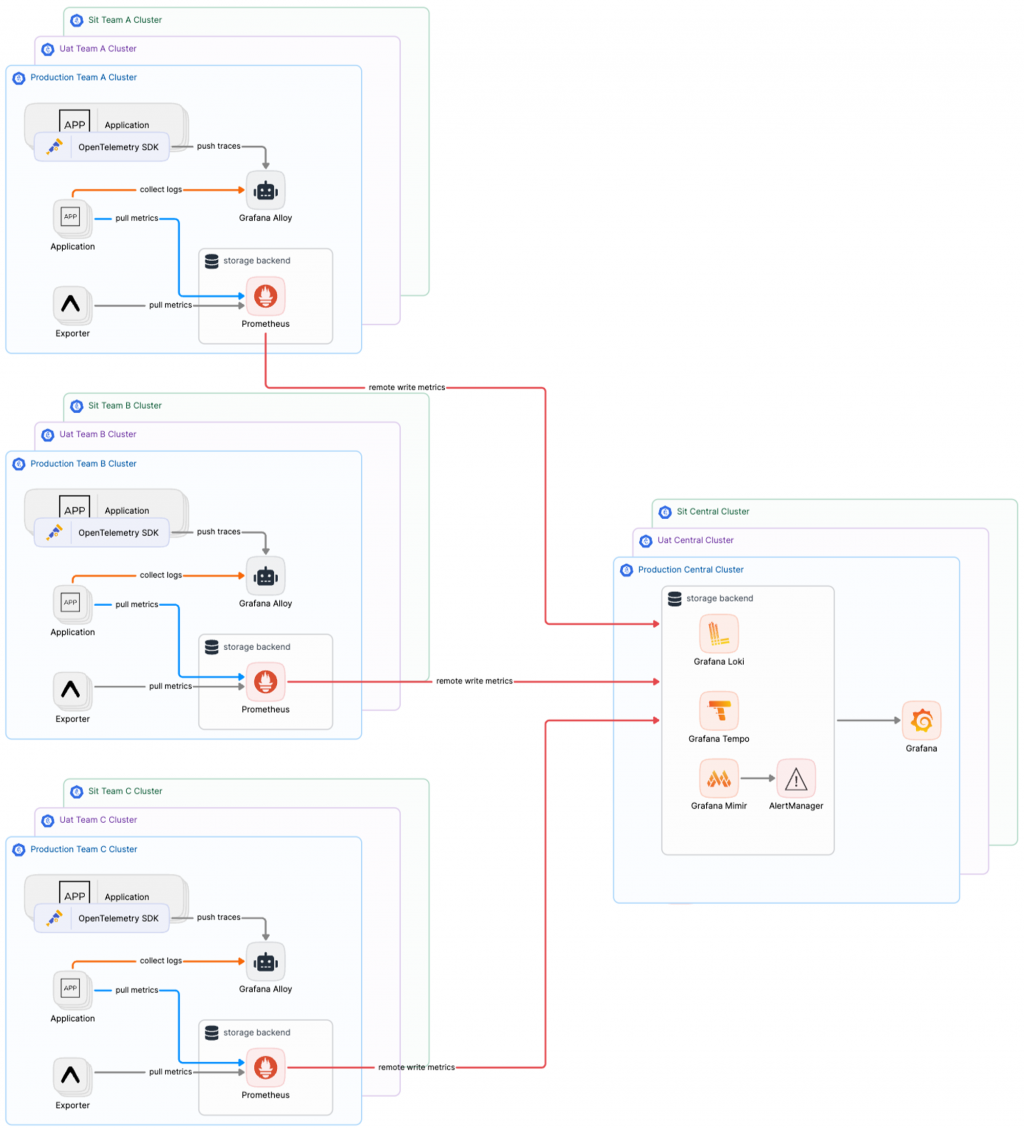
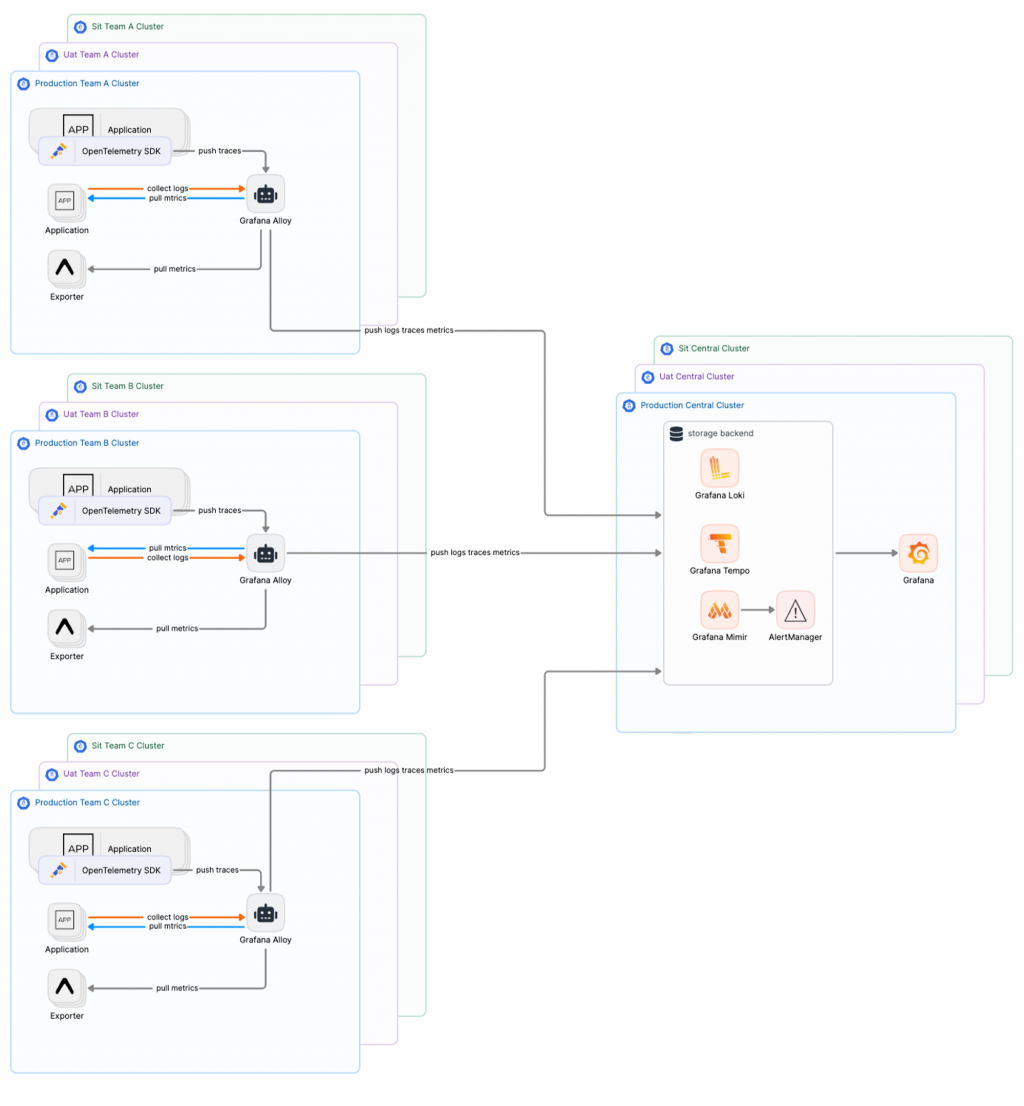
當我們的遠端指標儲存方案逐漸成熟時,我們可以考慮將原本的 Prometheus Server 模式轉變為 Grafana Alloy 的 Agent 收集模式。這樣一來,Grafana Alloy 就能成為統一收集所有指標數據的唯一端點,進一步強化我們的中心化架構。使用 Grafana Mimir 作為長期指標存儲後端,不僅能無縫兼容 Prometheus 的告警系統,還可以在過渡到 Grafana Mimir 的過程中繼續使用現有的告警和規則配置。通過這種轉變,我們實現了高度中心化的可觀測性基礎設施,不僅簡化了系統維護,還提升了整體的穩定性和可擴展性。最終,我們成功構建了一個完善的中心化可觀測性平台,有效支持業務的持續成長。
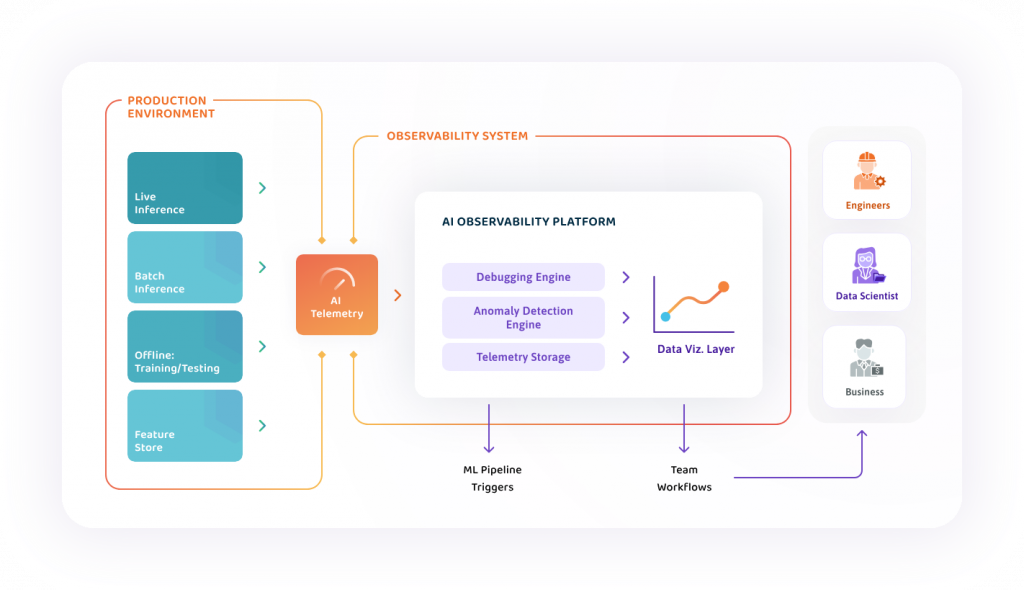
我想像中的未來可觀測性發展將邁向更高層次,而「平台工程」將是我們下一個注重的方向。隨著平台工程的逐步成熟,以及人工智慧和機器學習技術的快速發展,我們將迎來更加自動化且具預測能力的可觀測性基礎設施。這些新技術將使我們能夠將預測分析融入平台中,進一步提升預測問題的能力,讓我們在潛在問題出現前便能預見並進行主動的預防和處理。此外,當問題發生時,這些技術將幫助我們更迅速地緩解影響,最終達成更高效、更穩定的系統運營。這可能將大幅改變我們管理系統的方式和提升整個組織在面對技術挑戰時的能力。
到此為止,我們已經深入參與了一個中心化可觀測性基礎設施的誕生。至於平台工程的細節,這次系列中我們不會過多涉及。成功實現完整的可觀測性解決方案,離不開維護工程師、開發人員和運營團隊之間的緊密合作。我們需要持續進行經驗分享,幫助團隊理解這些技術的優勢,並根據實際回饋不斷打磨細節。最終,我們的目標是通過技術的不斷進步,確保我們的系統能夠應對未來更加複雜的挑戰。

